History of Computers - Bayesian Classification
By Chris Gillett
Introduction
Bayesian classification is based on Bayesian probability, an alternative take on the concept of probability.[1][2] Traditionally, in order to find the likelihood of thing A and thing B happening, you multiply the probability of thing A happening by the probability of thing B happening. However, if the likelihood of thing B happening is affected by whether or not thing A happens, Bayesian probability is needed. Bayesian classification is based on this principle, but allows one to determine an outcome based on previous outcomes. It is often used for artificial intelligence applications such as determining if an email is spam. Bayesian classification is a subset of artificial intelligence.
Overview
Bayesian classification provides a simple solution to complex problems such as text classification or medical diagnosis. A classic example of Bayesian classification is determining someone's gender based on their height, weight, and foot size. By first providing a handful of examples of men and women's heights, weights, and foot sizes, the process can then estimate whether someone is a man or woman when given their height, weight, and shoe size. This process is not a single algorithm, but a group of algorithms based on the overriding principle, Bayes' Theorem.
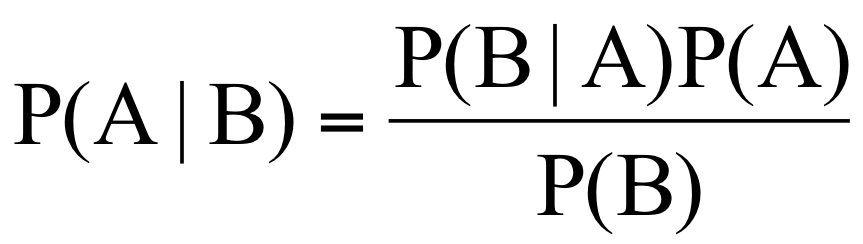
Significance
Bayesian classification made possible countless improvements in computing. Bayesian classification's applications with regards to spam filtering have been monumental in creating the widespread use that email currently enjoys[3]. Gmail, one of the more popular email services, was well known for their spam detection, which was likely based on the same principles discussed in this entry. ![]()